Results
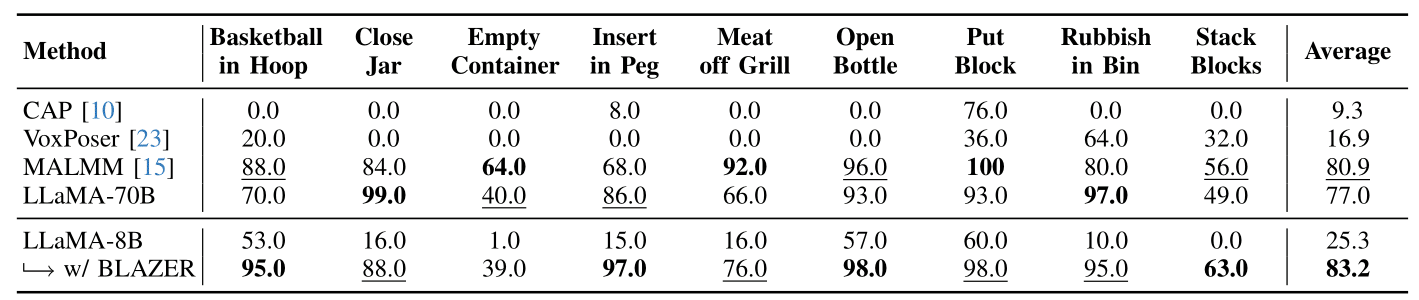
Comparison with zero-shot baselines. We report the task success rate (%) for different methods applied to the nine manipulation tasks from RLBench. With a small LLaMA-8B model fine-tuned with BLAZER, we are able to achieve the best performance. Note how LLaMA-8B with \( \text{BLAZER} \) considerably outperforms LLaMA-70B, which was used as \( \text{LLM}_\text{boot} \). This implies that \( \text{BLAZER} \) can yield LLMs that outperform their teacher models on manipulation tasks. The table highlights the best-performing method for each task in bold and the second-best method as underlined.

Real world results. We compare LLaMA-8B with \( \text{BLAZER} \) against LLaMA-70B on real-world tasks depicted. From quantitative results in the Table, we outperform the baseline, both on In-distribution tasks (similar to \( \mathcal{T} \)) and Out-of-distribution tasks, showcasing the generalization capability of \(\text{BLAZER}\).